

The Octopus And The Swordfish
If OpenAI is the next Google, Anthropic won't be its Bing
When people talk about Anthropic, they mostly describe it as the “second biggest AI startup”, after OpenAI. Many people know them through Claude, and know it as a “runner-up to ChatGPT”.
I don’t think this is a useful way to think about these companies - as a big and a small version of the same approach - and I don’t think it provides a good mental model for understanding how the overall AI market is taking shape.
I can understand why people think this about Anthropic. It’s always reported on in this framing. Reuters, for example, recently said:
Claude's traffic, a proxy for consumer interest, was about 2% of ChatGPT's in April, according to Web analytics firm Similarweb
You could read this and assume that Antropic is, at most, a tenth the size of OpenAI, but their revenues tell a different story. OpenAI has recently reported a $10bn ARR, while Antropic has reported $3bn. Anthropic is clearly behind, but a far cry from the 2% suggested by traffic data.
So what’s going on here? How can we explain the fact that everyone and their mother has heard of ChatGPT, while virtually no-one outside of tech has heard of Claude, but one is only earning 3 times more than the other?
The answer is that they are taking two different approaches to productisation (and with that, monetisation). I think these approaches are useful to understand, as they are informative for how the Generative-AI industry as a whole is likely to take shape.
I call OpenAI’s approach The Octopus, while Anthropic’s is The Swordfish.

The Core Tech is The Same
I’ll explain what both of those different sea creatures mean in a minute, but first I think it’s worth briefly understanding the ways in which they are both similar.
OpenAI, Anthropic and all of the other AI Labs started life by training “foundation models”.
They each took a huge amount of content (text, audio, video) and used huge amounts of electricity and huge quantities of GPUs to create synthetic content generators, which we called “foundation models”.
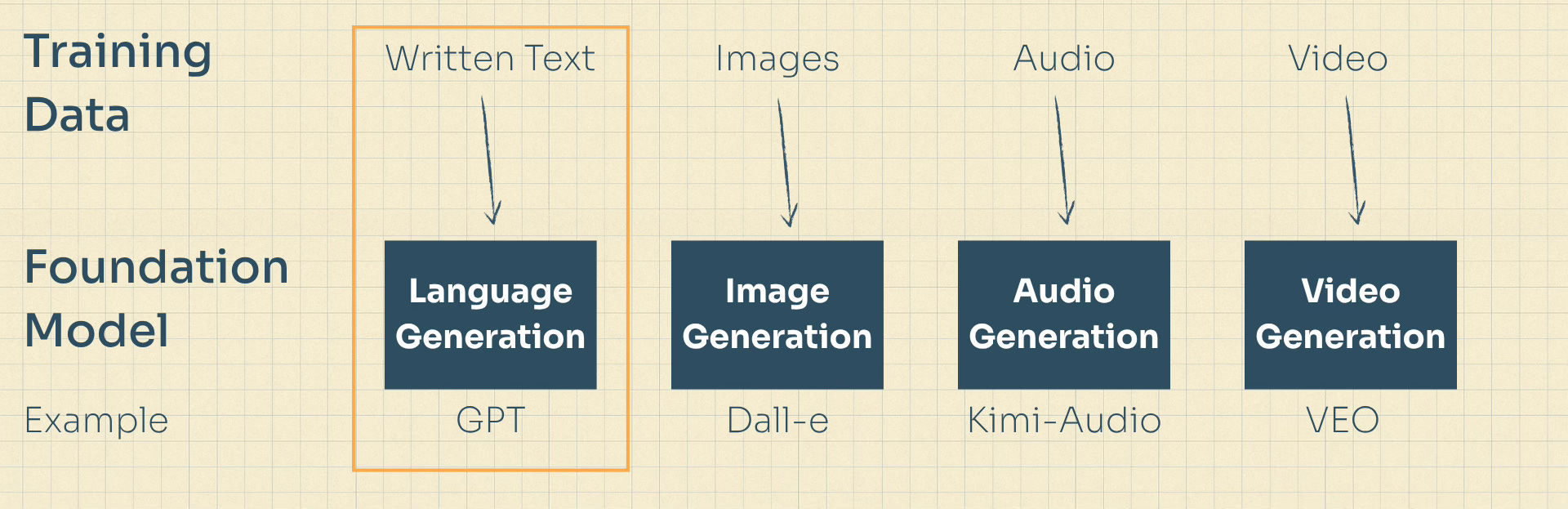
A synthetic content generator is very cool and very powerful, but not a very useful product. So what the labs have did next was take those pre-trained, foundation models, and apply some post-training (fine tuning) to make them good at one specific thing.
The problem, however, is that the foundation models suffer a bit from Homer Simpson syndrome - every time you teach them to be good at one thing, they get slightly worse at everything else.

The smart people in the AI labs have asked themselves “If we can only post-train this to be really good at one thing, what’s the broadest single thing we could pick”. So they picked things like:
Being a generally helpful assistant
Being good at using tools
Being good at reasoning out problems
I have called this the “wishing for more wishes strategy” and it’s working remarkably well.
They also asked “If we can only post-train this to be really good at one thing, what’s the most valuable single thing we could pick”, and have picked things like:
Being good at writing software
Being good at making videos
Being good at creating images
Being good at research
The Productisation Has Been Muddled
The AI Labs have taken their base-layer foundation models and fine-tuned them into a series of standalone models, each of which are excellent at one specific thing.
The productisation of these models is at a very muddled phase right now. You can see it in the leaderboards on LLM arena, where all of the labs are trying to make separate models that are great at all of the things (Writing, Vision, Coding, Maths, Text-To-Image, Search etc.).
You can also see this manifested in ChatGPT’s absolutely chaotic naming convention for their models (4o is not a precursor to 4.1, and is different from o4), with incredibly vague descriptions for each:
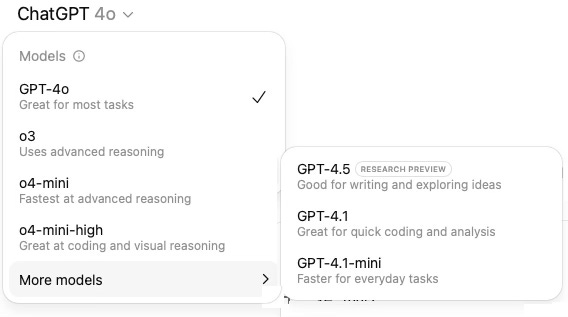
So we find ourselves in mid-2025 with a wide array of models that are becoming quite good at some horizontal tasks (being assistants, searching and researching, reasoning, browsing the web) and some vertical tasks (making images, writing code, making videos).
How will these be productised?
I think there are two broad approaches emerging here - the Octopus and the Swordfish.
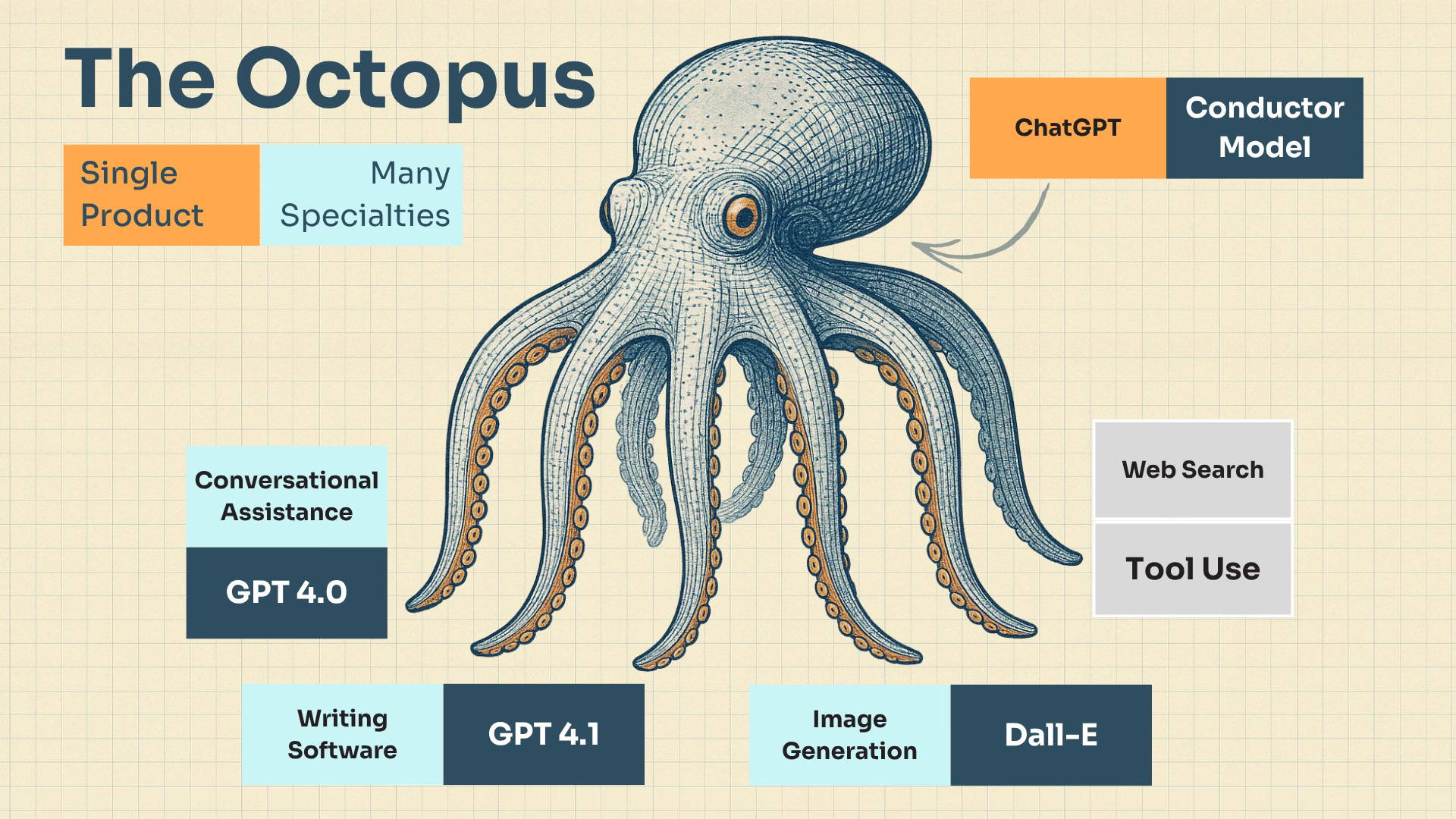
The Octopus strategy will involve using one of the horizontal models (a good assistant) as the gateway to an array of specialist models. It will productize as a single interface which can cover a wide-variety of taks and request well. It will be a mass-market, jack of all trades, dominating a category.
The Swordfish strategy will use one of the vertical models to productise a single specialisation. One model might power a wide variety of and products, split across multiple companies. It will be a deep expert, powering entire verticals.
OpenAI’s Bet - The Octopus
You don’t need me to tell you that ChatGPT has been phenomenally successful. It has over 500 million weekly active users and still growing strong.
ChatGPT, like Google before it, has become the default starting point for so many users when they want to turn to AI to give them an answer or solve a problem.
OpenAI’s bet is that ChatGPT can become the conductor, the orchestration layer, that receives a user’s request and then decides which model or tool would be best at solving that.
The product is singular. It is the head of the Octopus. But also (like an Octopus!) each limb is a brain too. Maybe even more ‘intelligent’ and specialised than the one in the head.
We can see products moving in this way. ChatGPT is getting better at automatic tool use. Newer models like Google’s Gemini 2.5 Pro and Moonshot’s Kimi K2 are built on a Mixture of Experts architecture, which has this orchestration concept built-in.
The Octopus Companies
I like the Octopus as a mental image of a company splaying out broadly, trying to cover as much surface area as it can wrap it’s arms around, aiming to be broadly appealing and useful to as many people as possible.
OpenAI have ChatGPT with a very popular free version, which is already facing tough competition from Google and Meta, both of whom have large existing user bases (Google reports 400m MAU for Gemini, Meta reports 1bn MAU for MetaAI) and their own advertising platforms to support a free service.
ChatGPT is facing less competition for its paid version, which is also putting up very impressive numbers, with 20m subscribers in April (probably 23m-25m now). Google Gemini is the other big player here.
The obvious analogy here is with search. Google was the Octopus in this space, becoming the go-to destination for a generic search query, building out arms in product, maps, flights and more. But others were able to find their own territory too. Amazon for products. YouTube for videos.
I don’t know what space ChatGPT will eventually settle into and try to own. Maybe they take “I need to learn about x” from Google, or “I need to get a productivity artefact made” to take doc writing and email drafting and slide creation from Microsoft. The battle will be fierce.
After ChatGPT, Gemini and MetaAI, there are many other, very distant runners up in the Octopus race. Anthropic’s Claude doesn’t even come close, which is why the Octopus race is not the one they should be trying to win.
Anthropic’s Bet - The Swordfish
I think Anthropic’s most likely path to success will be a narrow approach, not a broad one. A specialist, not a generalist. A swordfish, not an octopus.
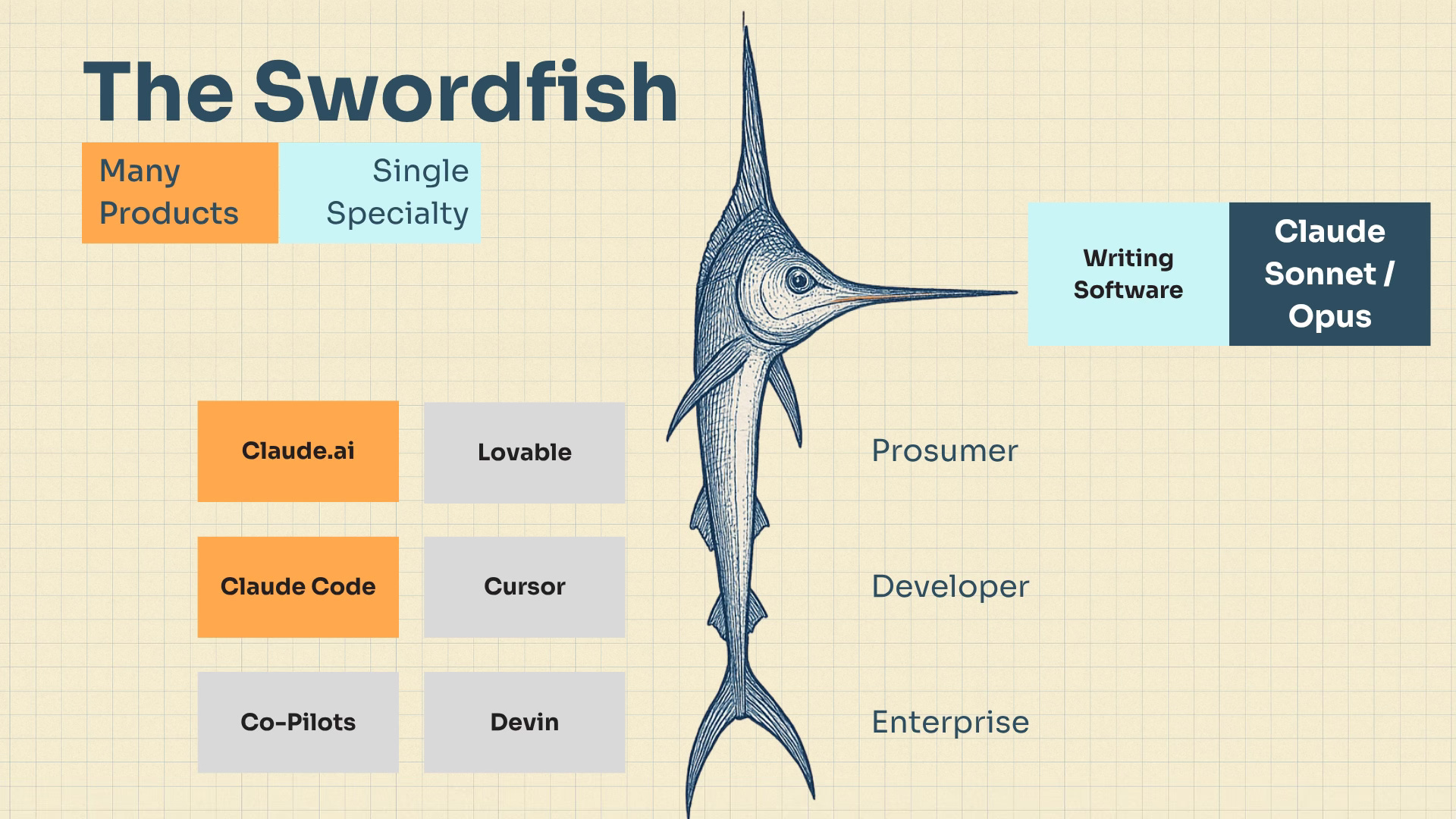
This path involves a single model (or a small set of models) that get better and better at doing one specific thing. In Anthropic’s case, it’s writing software.
One could go to The Octopus with a request to write some code (and many people do), but if you’re serious about writing software - if you do it for a living - you want to use the best model possible.
Currently that’s Anthropic’s suite of coding models. Sure, the leaderboards might score some of the others higher, but the usage and revenue figures would suggest that Anthropic’s Claude is leading the pack.
And this would make sense. If you are a person looking to use AI for one specific task (writing software), day after day, it will benefit you to try out all of the options and then select the one that works best. Speaking from personal experience, Claude Code is such a significant improvement over the others that it has saved me hours per week (and that’s just messing around with side projects).
Coding is the first specialisation to fit the Swordfish Model because it is a reasonably large market (there’s at least 2m developers in the US), and it’s one of the easiest specialisations for language models (it’s a group of languages, there are many right answers, and it either works or it doesn’t, so you can do fine-tuning on it at scale), but others will emerge too.
I’d expect to see attempts to build Swordfish approaches in Legal, Medical, Educational and other similar domains in the near future.
The Flywheels Are Coming
You might be reading this post and wondering… don’t Anthropic have an octopus-like offering too, in their Claude Chatbot? Don't OpenAI and Gemini and Mistral offer swordfish-like approaches in their various models?
Yes, that’s true…. for now. It won’t hold for long.
In the early days it makes sense for all of these companies to try to wrap their arms around as much of the market as they can, to make many bets while the future remains so hard to predict.
I think they’ll still keep doing this for a while longer.
But soon two forces will take hold, one technical and one economic:
Usage flywheels will be found and developed, whereby the model which gets used the most will have the most opportunity to improve.
On the technical front, the early gains in each new generation of model have been so large that they have overpowered any early flywheels. The benefit of moving to the newest model significantly outweighs the cost of switching. Eventually this progress will plateau and both Octopuses and Swordfish models will begin to find durable flywheels.
For the Swordfish, being the best in one domain will likely have such strong competitive advantages that companies like Anthropic will be forced to focus all of their attention in winning that race.
If a competitor can take a big chunk of the world’s software-writing workload, then their product can learn and improve faster and Anthropic won’t have a break-away success.
Swordfish will be pushed to specialise.
They will also be pushed to allow other companies to build products using their models, because they want as much software writing to flow through their system as possible.
Anthropic’s models are being used to power both professional products like Cursor, Devin and Windsurf , and prosumer products like Lovable, V0 and Mocha.
You can see in the diagram above that the Swordfish powers the entire product vertical!
There is a delicate dance here between these companies. Each of the smaller products will hope that several of the AI Labs (not just Anthropic) continue to invest in coding models, which will commoditise them and prevent them from gobbling up all the margin in the space.
Conversely, Anthropic are hoping to find flywheels and network effects that will translate their usage-advantage into an un-catchable product advantage, at which point they can extract most of the margin from the value chain (leaving the smaller companies to act as resellers and distribution channels to bespoke niches).
I don’t think it’s fully clear where the usage flywheels and network effects will emerge here. If it’s not at the model layer, then it’s all to play for. All the other labs can keep building models that are only 3-6 months behind Anthropic’s and, if their progress eventually plateau’s, it will become a commodity layer.
It will be exciting to watch this develop!
It will also be exciting to see where other Swordfish emerge, beyond coding.
Octopus Flywheels
Equally for those taking the Octopus approach, it will be very interesting to watch as they each try settle into the largest domains possible.
The flywheels and network effects seem more apparent here. Search is again the obvious analogy here. Google became dominant first - the go-to place for general queries. The more people searched, the more Google learned, the better its service became and the harder it was to catch.
I think ChatGPT and Google are both in strong very strong positions here. I’m not sure if the “general knowledge query” market will support one or multiple players in the future, we’ll have to see how deep the usage flywheel is.
The “I want to get a knowledge work artefact produced” seems like another large domain for an Octopus to own. OpenAI, Google and Microsoft will all be vying for this.
In traditional search, Google didn’t dominate completely - Amazon peeled away “searching for a product”, YouTube peeled away “searching for a video”, Expedia and Booking.com peeled away “searching for a hotel”.
New Octopus models will spring up in AI too. They will overlap and compete.
I’m less optimistic for the application layer here, built on top of the Octopus. It is a very hungry model that will gobble up all the margin in sight. Even if they don’t get data usage flywheels or network effects, they will build consumer habits and brand recognition that will be hard to compete with.
The nature article I linked to above, about the real-life Octopus, has an informative quote:
What does an octopus eat? For a creature with a brain in each arm, whatever’s within reach.