

How to Make Realistic Predictions About AI
We can only predict the economic impact by understanding the fundamentals
Will AI automate my job? Are we about to enter a period of massive unemployment? Will half of all entry level jobs disappear next year? Which industries will face the biggest impacts?
These are important economic questions, but it’s proving difficult to find sensible analysis on how to answer them. When the leading AI CEOs are all professing to be on the brink of super-intelligence, it sucks up all the oxygen in the discourse. Who can reasonably predict whether “AGI” (which hasn’t been created yet) will take 12 months or 12 years to ripple through the economy?

Imagine we were in the late 1800s, watching Edison and Tesla figure out electricity generation, but most of the popular discourse was about what will happen to the economy if we have infinite power.
Abstract chatter about power, (much like abstract chatter about intelligence) would have been such a distraction from the many real and interesting questions about the new technology and is impact. Does electricity replace steam power? Will we electrify just businesses or homes too? Will the government or private enterprise pay for the grid? What are electricity’s limitations? Will the big winners be power plants or appliance makers or someone else?
The hyperbolic discourse on AI is distracting us from asking the real questions. Not trying to predict what happens when we unlock infinite intelligence, or birth god from a machine, but rather to predict what happens if this technology as impactful as the smartphone or the internet, or even the printing press or electricity?
So how do we get equipped to make better predictions about AI?
I believe that starts with an understanding of the fundamental building blocks of the new technology. From there we can start to predict the ways in which it will naturally improve with time, where it will face limits and where it will need new discoveries or step-changes to be unlocked.
Where linear (or even exponential) growth is possible, we can chart the potential impacts on businesses, industries and the economy. Conversely, for areas which still require new discoveries or breakthroughs, we can apply some conservative skepticism to our forecasts.
That’s what this post is about. I want to explain the key, foundational building blocks of this new technology in a way that a professional (but non-technical) reader can comprehend, then explore ways to use that understanding to make better economic predictions.
Machine Learning is The New Discovery
In the early 1900s the Ford Motor Company famously adopted the assembly line. It was a new way to organise a factory, pioneered in the late 1800s in meatpacking plants and then spread to other industries.
What term would you use to describe the assembly line? A technique? A methodology?
I would call it a technology. An organising technology. It was a way of organising factories to build a product. It was transformative.
Machine Learning is a technology, in this sense. It is a way of using trial and error to embed an understanding of our world into a computer, then using that understanding to solve problems.
Imagine if we had found a way to show a schematic drawing of a shoe (or a car or a refrigerator) to a factory, then watch as the factory uses trial and error to self-configure into the best shoe-assembly-line possible. I think that would be something akin to machine learning.
Let me explain it better with an example….
How Machine Learning Makes Predictions
Do you remember the T9 predictive text on your old Nokia phone? You’d mash a few of the numbers on the keypad and the T9 would predict the word you were trying to type.
Pressing 2 then 2 then 8 magically produced “Cat”.

This worked because the engineers at Nokia1 saved every word in the English dictionary into a database, then mapped a set of keypad numbers to each word (Cat = 228, but also Bat = 228), then ordered them by frequency of use (Cat is 228-1, Bat is 228-2).
That last part is important. You want to make the keyboard more useful by having it guess the most likely word that the user is trying to type. To make this happen, I assume some engineers used thousands of pages of digital books or encyclopaedias to understand how frequently every word tended to occur in the English language.
There’s about 50,000 words in the English language, so you can imagine that this wouldn’t be too hard to achieve with the help of some basic computer scripts.
Count all the “cats” in your sample. Count all the “bats”. Order by frequency.
You could use this process to make a very rudimentary text predictor on a modern smartphone too. With a full QWERTY keyboard, the job is slightly different. What you’re trying to do here is to guess what the word might be before it’s finished.
So when someone types “Ca” it would be very useful to suggest “Car” or “Cat” or “Cash” or “Caput”, but there are 12,216 words that begin with Ca, so how do you know which ones to suggest?
You can start by gathering large amounts of text like the Nokia folks did, from books and websites and wikipedia, and analyse the distribution of letter sequences. If you look at 2-letter distributions (bigrams), for example, you’ll find that O is the most common letter to follow c, then E, A and H. It’s never followed by J, V, W or X.
This is a distribution that you can save in a database. It’s 26 initial letters x 26 following letters. That’s 676 2-letter frequencies to record and sort.
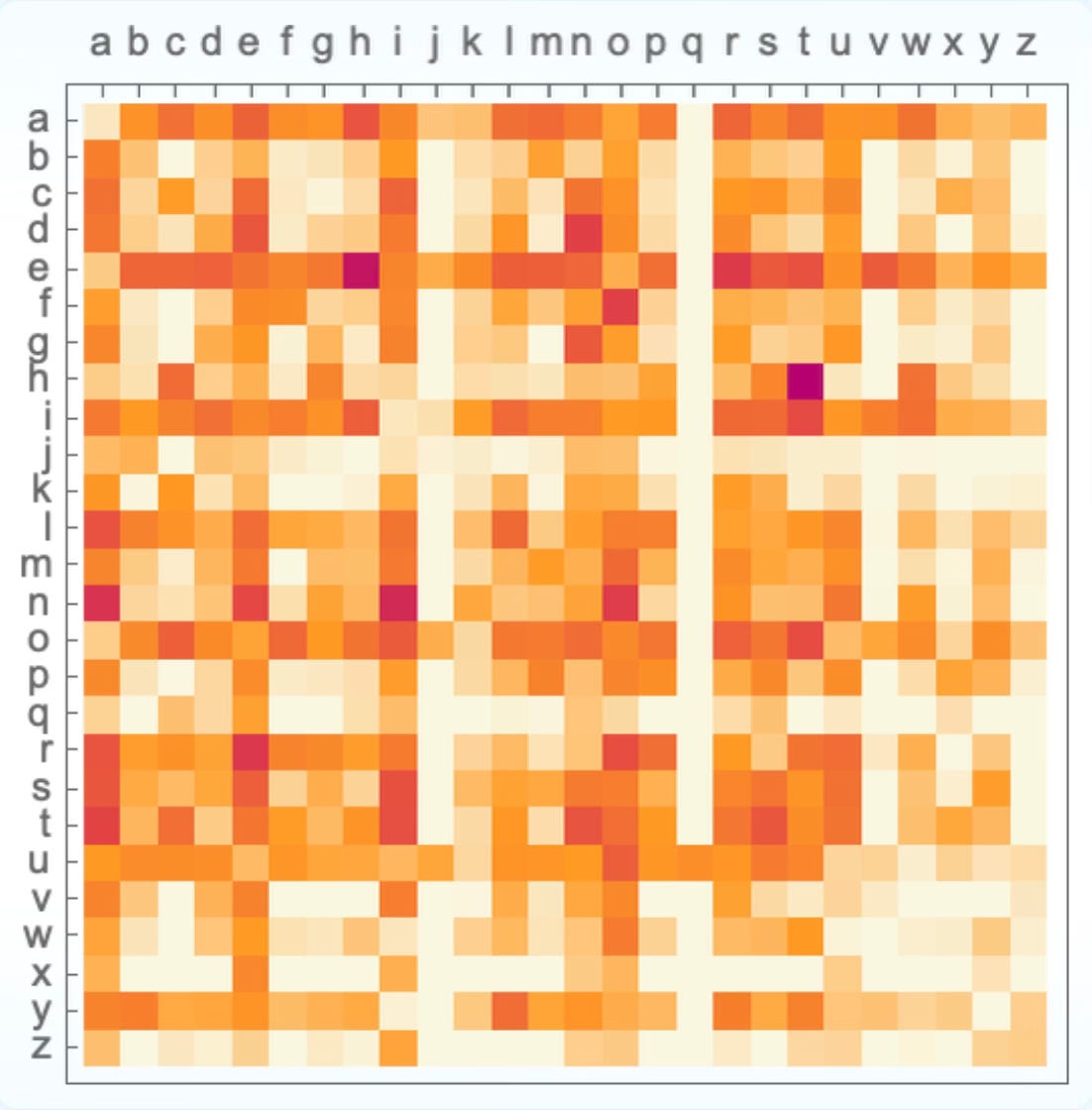
But we can make our predictive system better than this. If the user has typed “Ca” we should have a database of the most common 3 letter distributions (trigrams). This is 17,576 frequencies to store and record.
That helps us predict “Car” and “Cat”.
What about “Cash”? To get there we’d need to map all the 4 letter distributions, which is about half a million.
You can see the problem here. The complexity is scaling exponentially. Our phone battery will be “caput” long before our keyboard manages to suggest it as a word.
And besides, what we really want to be doing is predicting word frequencies, not letters. Instead of taking into account the previous letters to predict the next letters, what we really want to be doing is taking into account all of the previous words in the sentence to make a useful suggestion for the next word.
“I like to drive my ca”
“I have a dog and a ca”
A good system would ideally make two different suggestions for finishing these sentences.
To analyse and record all of the word frequencies in the English language, then analyse and record all of the two word (“pet cat”), three word (“drive my car”), four word pairings is technically possible, but it becomes harder and harder to scale a useful solution.
It’s one of those cases where you quickly end up with more combinations than there are grains of sand on the beaches, or stars in the night sky.
What you need is a way to learn the underlying, generalised patterns of word distribution in the English language, if such a thing even exists. If you had that, then you wouldn’t need a written record of each specific word-combination-frequency, you could just use the patterns to estimate the frequencies for any given combination of words.
Can that be done?
Is There a Pattern to Handwriting?
Let’s switch briefly to a different but related computer problem - reading handwriting.
How do you teach a computer that this is a 4?
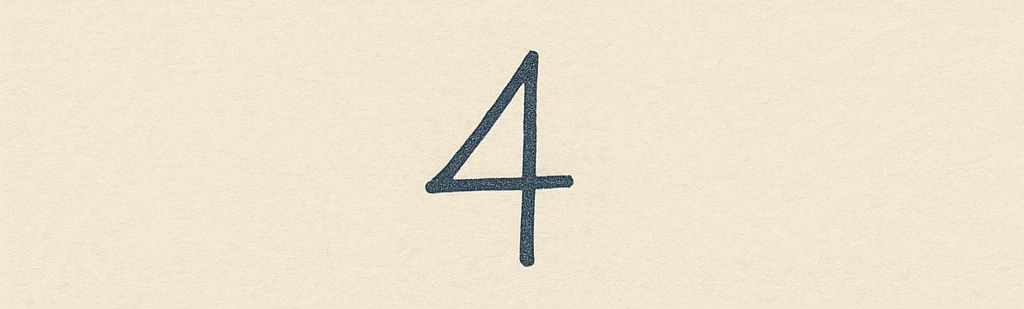
There’s probably some simple ways to “code” a solution, to describe in mathematical terms the shape and contours of this figure, but this approach quickly gets difficult when you try to code a single set of instructions to recognise any of these as a 4:
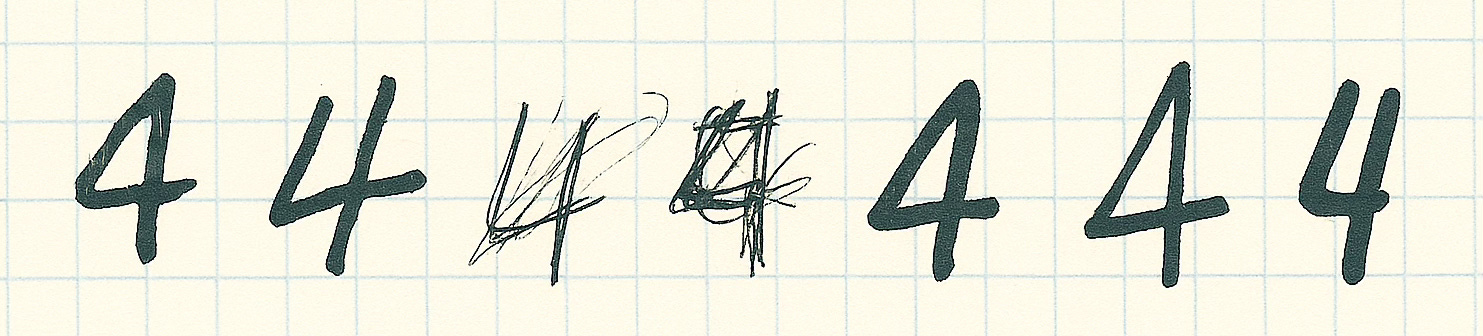
To the human eye, these are all clearly the number 4. Even if you’ve never seen a 4 drawn exactly like this, you can still recognise it as a 4. What is going on in our brain that lets us do this?
There must be some core characteristics of a 4 that we have internalised that we use to recognise this. The cross in the middle, paired with a triangle shape in the top left, sometimes with an open top, sometimes closed.
If we tried to achieve this any time before roughly 2010, it would involve a human writing the characteristics of a 4 as rules in code, then we would feed the data into rules (show it the image) and it would give you the answer (“this is a 4”).
This was fairly hit and miss, and difficult to scale.
The new trick we discovered with Machine Learning is that we don’t have to first understand the characteristics of a 4, then describe them to a machine (i.e. write the rules into code).
With Machine Learning we instead feed the machine a huge amount of data (show it lots of images) and tell it the answers (which ones contain a 4 and which ones don’t), from which it can learn the characteristics (create a model of the rules).
Old: Rules + Data = Answers
New: Data + Answers = Rules
Training a Model
The “rules” in this sense aren’t rows of code in a script, they’re rows of neurons in a network, with connections between them. We call it a Neural Network and it looks something like this:

I like to imagine them like rows of soccer players in formation. Or better yet, rows of foosball players on a foosball table.

Imagine that each player here is a little robot who can receive a football from the row behind him, then make a decision about who in the next row to pass it to.
You could imagine one robot player having some simple internal logic like “If I receive the ball from anyone on the left side of the field, I’ll pass it straight forward. If I receive it from the right side of the field, I’ll pass it on to a random player on the right”
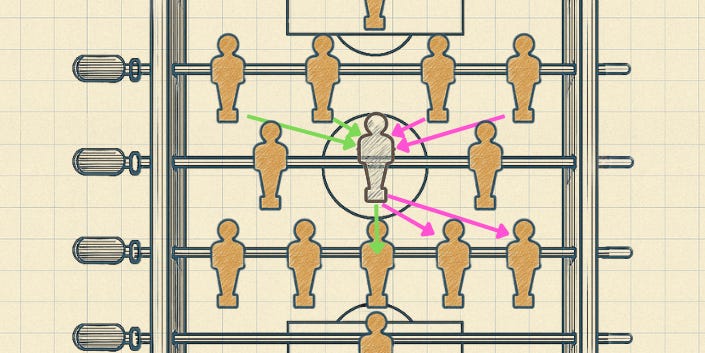
Now imagine there are some numbers written on the football.

Each robot can have some logic that says “I’ll use the information of who I received the ball from and what the numbers are to decide who to pass it on to”.
This might sound very simple, but it’s pretty analogous to what’s happening in a neural network. Each robot foosball player is a “node” or a “neuron” that has very some simple logic (“parameters”) for assessing the numbers on the ball, based on who they received it from. The connection between any two players can be described in simple mathematical terms (“weights”).
So how do robot foosball players help us read handwriting?
Let’s imagine a 10*10 grid, drawn on a piece of paper, where each cell can be either shaded in with a pencil or left blank. You could write the number 4 in that:
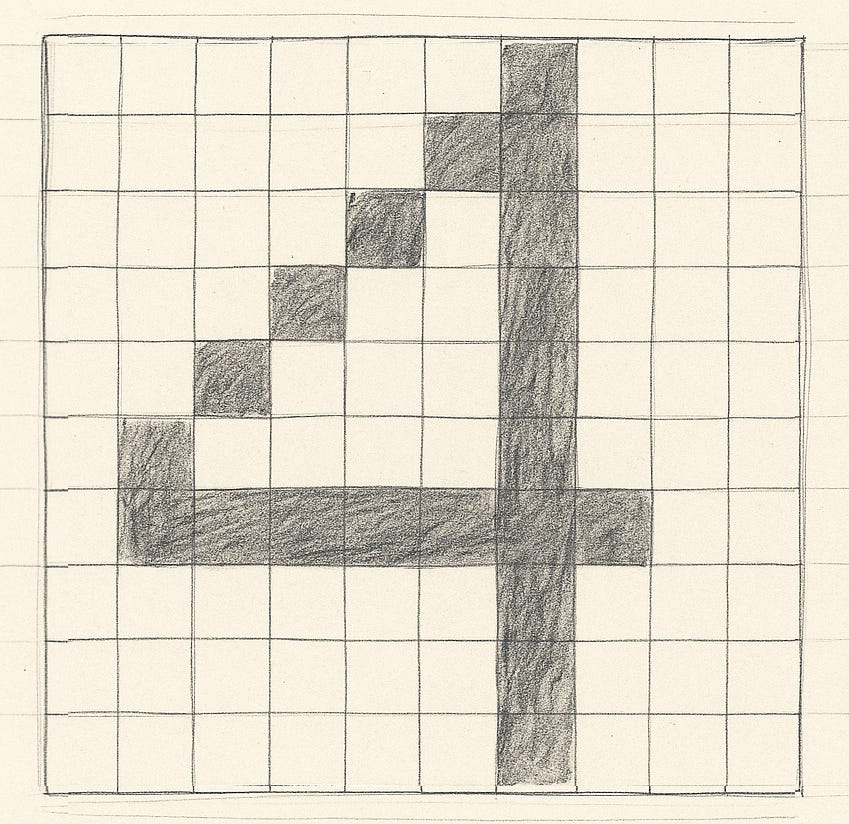
For each square, you could assign it a number. Say 0 if it’s empty, or 1 if it’s black.

The entire image could then be represented as a long number, a string of 100 digits.
Put that 100 digit string on the football, place it at the top of the table, then watch as it’s passed from row to row. Each robot player has his own little internal logic that he uses to decide where to pass the ball next.
“I’ll multiply it by 3, then add 100, and if it’s even I’ll pass it right”
“If the first half is larger than the second half, I’ll past it left”

It finally reaches the front row, where you’ve placed 10 strikers. Number 7 gets the ball and scores the goal.
Congratulations! You’ve built an automated foosball machine that can read numbers on a page. This is your “handwriting recognition model”. It has guessed that “7” is the written number.
How does it preform? Absolutely terribly!
The ball is just bouncing around at random, like a pinball, so of course it will be no better than chance. So you devise a system to improve your machine’s odds.
First, you rent a big warehouse. Maybe an old abandoned pool hall with some moody lighting. (This is your data centre)
You set up 10 foosball tables. Each with identical rows of robot foosball players, but with varying instructions so that no two tables are the same.

You start putting footballs into them. Each ball represents an image with a handwritten digit on it. You put 10,000 footballs through each robot foosball table. It’s a long day.
How do they perform? Also rubbish!
Most of them get the right answer 10% of the time (i.e. random chance). Some are even worse. 9%. 8%. But one gets it right 11% of the time!
Still terrible. But better!
So you take the internal logic of the robots on the 11% table and replicate it across the other tables. Then you tweak each table a little bit at random, so that the parameters are a little bit different. Then you run the experiment again.
10,000 footballs, each through 10 foosball tables, each analysed and passed on by a slightly different set of rules. You order a pizza while you wait, this is hungry work.
Now a single table gets the right answer 12% of the time! You copy/paste the robot logic to the other 9, then randomly tweak each one, and you go again. And again. And again. And again.
You text your partner “don’t wait up”, you’ll be working late tonight.
By midnight you’re getting it right 30% of the time. At 3am it’s at 60%.
As the sun rises the next morning, you’re bleary eyed, delirious, but ecstatic. Your robot foosball machine is getting the number right 98% of the time.
Believe it or not, this actually works! This is model training.
In real life, the numbers involved are much, much bigger, but the principle is the same. One very basic character recognition model, for example, was trained by using 97,000 images to fine tune the parameters on 2.8m weights (robot foosball players).
OpenaAI’s GPT-4, would be the equivalent of a foosball table with a few hundred billion players.
The real life version is also incredibly time and energy intensive.
[As an aside, if you used traditional CPU microchips to process this, it would be the equivalent of running 1 ball through 1 machine at a time. GPUs, which were invented to display and update all graphics on a screen at the same time, turned out to be perfect for the process of running millions of footballs through millions of machines concurrently. NVIDIA designs the best GPUs and that’s why they’re worth a trillion Dollars now.]
Concepts of Roundness
The foosball table is what we call a “model”.
Through the process of repetitive predictions and iteration, it has discovered the patterns of human hand writing and encoded them into its parameters and weights. If we lifted the hood and looked at how the foosball players were passing, it might look something like this:
Every time a ball is processed by the second row, the numbers 1, 4 and 7 are consistently passed down right side of the board. All the others are passed down the middle. Then, after the next row, numbers 0, 6, and 8 are consistently passed down the left side.
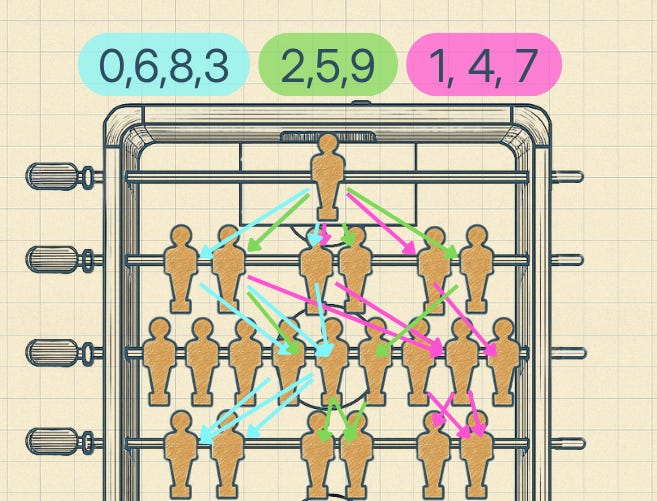
In a way, these rows seem to be sorting for “roundness”. The logic embedded in the robots has evolved to analyse the 1s and 0s of a pixelated image and mathematically discern the presence of a “round edge”. Anything without a round corner, like a 1, 4 or 7, goes right. All else goes straight ahead.
The next row is then separating the numbers with only roundness (e.g. 0, 8) from numbers with a mix of roundness and sharpness (e.g. 2, 5).
At this point, you might expect that that the model would separate some of the 3s into two separate groups:

It is likely that another row further down the board would have evolved a method for re-grouping these (and the 9s and some of the 5s). Ditto for the open and closed 4s.
I want to pause and reflect on how profound this is. Through the process of trial and error, we now have a technology that has discovered abstract concepts (roundness, sharpness) in a human domain (handwriting) and can now analyse the patterns in data to identify those concepts.
Much More Than Handwriting
The model we’ve been talking about takes very simple inputs. A string of 100 digits representing a 10 x 10 grid of black and white pixels.
The same concepts still apply if we scale that up. A modern iPhone, for example, usually takes 12 megapixel photos. That’s 12 million pixels, in a 4032 x 3024 grid.
Instead of each pixel being represented by a 0 (white) or 1 (black), you could have gradients of 0 to 100, representing the percentage of black or white (i.e. shades of grey).
Or better yet, each pixel could have an RBG number, representing the quantity of Red, Green and Blue in it. Now you can use a string of numbers to represent a full color, high definition image on each football as an input into your image recognition model.
With that you can start to train a model that looks at images and predicts whether or not it contains a cat, for example. You might set your foosball table up to have two strikers in your last row, representing “Cat” or “No Cat”. Or you might have a hundred strikers, each representing a different “Percentage likelihood that this is a cat”.
A well trained model - which has seen hundreds of thousands of cat and non-cat pictures, taken guesses and then replicated when successful - will start to embed core concepts of cat-ness.
Even though it’s just a collection of numerical parameters, I think it’s reasonable and useful to say that the overall model “understands the core concepts of a cat”. Just like the roundness of numbers, we can expect this cat-prediction model to have embedded concepts like “tails”, “whiskers” and “pointy ears”.

But it will have also embedded lots of other concepts that we can’t understand. These models are embedding concepts of numbers and cats in ways that elude narrative descriptions. This is part of what makes their progress and limitations so difficult to predict.
This is Predictive AI
At this point in our journey we have created Predictive AI. As you might have noticed, it’s not yet Generative AI (drawing pictures of cats, or writing out numbers and sentences), but it is nonetheless very powerful.
The technological stars aligned about 10 years ago and Predictive AI became commercially practical. Since then we have been using it to do voice recognition, social media recommendations, fraud prevention, financial forecasting, medical diagnostics and a whole host of other applications.
We can now show machines satellite images of agricultural land and they can predict future crop yields. They can look at IVF embryos and predict which will become babies.
The potential is enormous. Wherever we can gather enough data on a certain concept, we can train machines to understand the patterns within that concept and use those patterns to make predictions.
There are many limitations here too. To train a model you don’t just need lots of data, you need lots of labeled data. When you feed 10,000 images of cats and dogs into your foosball table, you need to know in advance which ones actually contain cats in order to reward and propagate the best models.
This can be costly and time consuming to assemble.
The quality of the data is wildly important too. Predictive AI models are very good at understanding the underlying patterns in the data you feed it, but if the data isn’t fully accurate, then the model won’t predict the real world. Data is just a numerical representation of the thing, not the thing itself. The map is not the terrain.
We also don’t often understand the “concepts” the models are embedding. In addition to concepts like the “roundness” of numbers or the “pointed ears” of a cat, they do things we don’t understand or expect. One infamous example is a model that predicts which skin moles might be cancerous. A concept this model learned is that all of the cancerous moles were more likely to “have the look” of images taken in a professional, medical setting (the presence of gel or writing on the skin, a measuring tape in the picture etc.), whereas non-cancerous images in the training set “had the look” of images taken by non-professionals, at home.
The biggest constraint of all is that all machine learning models are domain specific. The model which learns to analyze financial transaction data to understand patterns of fraud can’t also be the model that predicts what Netflix show you might watch next. The handwriting foosball table won’t discern cats from dogs.
Predictive AI an exciting new technology. The technological stars of commercial viability aligned about a decade ago (compute power, available data etc.) and I believe we are still in the early days of reaping the productivity benefits that Predictive AI will bring.
It is magical, but it is not a path to anything like “generalized” AI. I think about it as if we have found a new way to build factories, whereby we invest huge resources to grow an assembly line, we don’t fully understand how it works, but it can make one output really, really well.
So where then is all this AGI hype coming from? Well that all starts when we trained some models to predict language.
Language Models Are A Cheat Code
Let’s return to our text prediction problem from up above. If you recall, we were trying to build a system that would predict the next word in sentences like these:
“I like to drive my ca…”
“I have a dog and a ca…”
We knew we couldn’t write instructions that were complex enough for software to do this well, so instead we yearned for a way to “learn the underlying, generalised patterns of word distribution in the English language, if such a thing even exists. If you had that, then [..] you could just use the patterns to estimate the frequencies for any given combination of words.”
What we need is a Language Model. That sounds like something machine learning could produce!
The process of training a language model is quite similar to our handwriting and cat-detecting models. You can start by taking any English language text. For example, this paragraph from the Wikipedia article on Cats:
It is commonly kept as a pet and working cat, but also ranges freely as a feral cat avoiding human contact. It is valued by humans for companionship and its ability to kill vermin. Its retractable claws are adapted to killing small prey species such as mice and rats.
You would then translate that paragraph into numbers, like we did with the pixels in an image. You could give each word in the English language an individual number. In GPT, for example, that paragraph looks like this:
[3206, 382, 22378, 13185, 472, 261, 5716, 326, 4113, 9059, 11, 889, 1217, 33269, 42545, 472, 261, 8510, 280, 9059, 49354, 5396, 3701, 13, 1225, 382, 42276, 656, 23011, 395, 154008, 326, 1617, 8285, 316, 15874, 13821, 258, 13, 13974, 125668, 562, 154893, 553, 45061, 316, 29374, 3291, 78166, 15361, 2238, 472, 44267, 326, 52238, 13]
We call these word ids “tokens”. Language Models like GPT have about 100,000 tokens, one for each dictionary word, numbers, characters, plus some for common word snippets like “ing”, “ize”, “un”.
With this “tokenisation” we can convert the paragraph into numbers, etch them onto on our foosball and pass it through the model. The trick here is that we don’t write the full paragraph, instead we start with just first few words:
“It is commonly kept as a….”
Or in token form:
[3206, 382, 22378, 13185, 472, 261]
The model is successful if it can guess the next token in the sequence, “ pet” [5716].
The analogy of the warehouse full of foosball tables still applies. Training a language model looks like running thousands of sentence snippets through your 10 foosball machines and seeing which one gave the correct next words the highest probability score. Replicating that table, tweaking, then going again.
You can do that again and again and again. You can take every wikipedia article ever written, then every webpage ever written, then every book ever written. You tokenise them. Break them into snippets. Then go again. And again. And again.
Soon enough, your language model will start to make accurate predictions.
When you give it the sentence “It is commonly kept as a …”, it won’t just predict “which word is next”, instead it will give you a percentage likelihood for all words in your token catalog.
“Pet” might have a probability of 20%, which is great, but souvenir might have a probability of “25%”. Which makes sense, the model didn’t train on Wikipedia’s cat page alone.

This is still useful for our text predictor keypad, but it’s not ideal.
What’s missing here is wider context. The model does a good job analysing the sentence, but it really needs to analyse the whole paragraph. Or more specifically, it needs to focus on some specific elements in a wider body of text, like the fact that the subject of the paragraph is “cat”.
This is where the breakthroughs2 have been made in the last few years. We have created ways for models to pay “attention” to key concepts and wider amounts of text, to help with this context building. (There is a certain way to arrange the neural network foosball table, it is called “transformer”, which is what the T stands for in GPT).
If you get enough samples of language, and you run it through massive models with hundreds of billions of weights, and you use enormous amounts of electricity to do this millions and millions of times, eventually you will have created a modern Language Model (often called “large language models”, or LLMs).
Just like the other models, the Language Model will have discovered and embedded within itself key abstract concepts about a human domain. Like the “roundness” of handwriting or the “pointy ears” of a cat image, it will have embedded concepts like “sentences”, “verbs”, “nouns” and “subjects”.

But it will also discover and embed higher level concepts, like “animal” and “plant”, or “poem” and “paragraph”, “things cats do” or “ways to sign off an email”.
You might have noticed something very magical that has happened here….
This language model is still constrained, like all other machine learning models, to be domain specific. It can only discover the concepts that exist within the patterns in data it has been trained upon. It just so happens that human language is what we use to describe all of the concepts in all of the domains that are important to us.
So training a model on language can actually produce one with embedded understanding of a wide variety of human domains.
What an incredible hack for getting us closer to a generalizable model!
Now you can see why there has been such excitement (paired with massive capital investments) in these models. All the power of Predictive AI, but with the promise of a application across an extensive variety of domains.
This has its limitations, of course. The most obvious is the quantity of training data needed. Language Models could not have been built without the internet. We have spent the last 30 years digitising all of human writing, so the timing has been wonderful, but the text available isn’t infinite.
It is unclear if running out of text for training will place a hard limit on this line of development. Some experts say that we can use synthetic data - text created by other models - but the risk here is that we begin training future models to detect patterns in each other, rather than uncovering new underlying patterns in human language.
Similarly, concepts that are written about frequently can be embedded in the models more successfully. Those which are written about less frequently, not at all, or after the training has finished, won’t be embedded well.
This is Generative AI
You may notice that we have so far only described a system that predicts the next word or two, like the one you see in email, messaging apps and word docs. Hopefully it’s easy enough to imagine how you can evolve these to be Generative AI Models.
If you feed a string of words into a Language Model, it starts predicting the next most likely word to follow. Then the next most likely word to follow that. And so on.
Crucially, this isn’t just based on simple word frequency in the English language, but on the embedded “concepts” in language. I think it’s fair and useful to say that language models have embedded understanding of those concepts.
This process can also be extended beyond text to sound (voice, music), images and videos. Images can be split into pixels and tokenized, ditto for the frames in a video. Audio waves can be represented digitally and chunked into tokens. We can train models to take any string of input tokens and use the same process can generate a string of output tokens.
This can even work across modalities. If you have enough training data of written descriptions of images, you can eventually input a string of text tokens (“A dog wearing a hat”) and the model can output a string of pixel tokens (a drawing of a dog wearing a hat).
We now have a myriad of these core, base level models for text, audio and video. They’re often called “foundational” models. Every few weeks a new one is released, with even bigger and better ability to match the patterns in human writing, speaking, music, drawing, images and videos.
Generative AI Is Probabilistic
Interestingly, we find that Generative AI works better when it doesn’t just pick the most likely word, but instead picks a random word, but heavily weighted by the probabilities. So the highest ranked word is still chosen most often, but not always.
This means that even with the exact same inputs, no two outputs are ever the same.

In this way Generative AI technologies are probabilistic, not deterministic. This is an important distinction when thinking about the kinds of tasks and work we be able to get them to automate.
A traditional computer is deterministic, which means that it will always produce the same output, given the same input. 2+2 will always equals 4. If we understand the steps involved, we can tell a computer what to do and it will do that repeatedly, reliably and at scale.
Generative AI, on the other hand, will produce statistically likely token strings - patterns that resemble concepts in human langauge - which are exceptionally useful when we can’t (or don’t want to) tell it specifically what do do. It’s useful when the inputs are unstructured or vary in unpredictable ways. It is not built to produce consistent and predictable outputs.
It will also make things up. If you input “The plot of Movie X is …” it will give you the pattern of a plot, using all of the concepts it has embedded, like “summaries” and “characters” and “movie reviews”. If reveiws of that specific movie were part of its training data, then it might produce an accurate summary. But if it wasn’t, or if the movie doesn’t exist, then it will just produce a statistically plausible sounding pattern of a movie plot.
How Generative AI Will Affect Your Job, Company and Industry
Now we get to the fun part - using our newfound technical understanding to make some economic predictions.
First off, you shouldn’t forget about Predictive AI. It’s still a relatively new technology, in the grand scheme of things. As long as there are patterns in reliable data sources that we can’t yet see (like the folding of proteins, or fraudulent transactions) then Predictive AI has plenty of runway left to improve productivity.
For Generative AI, I think it’s useful to imagine how these foundational models will be turned into products. So far, that has been happening in broadly two modes.
In Mode 1, the foundation model is merely a component part of a wider system (a product, a company, or a job). In the Mode 2, the foundation model is further refined to become the product.
Canva is a great example of the Mode 1, where generative models are just one part of a wider system. Canva uses a collection of language and image models to power functions in their graphic design app.

Their “Magic Studio” gives users a one-click button to remove the background from an image, or create a new background, to remove or erase elements etc. They do this by handing the image off to an Image Model, then surfacing the result back in the Canva editor.
They also provide the ability for a user to type “Make me an image for an instagram post wishing my plumbing company a happy birthday”. This gets passed off to a Language Model, which generates the code for a new Canva template, then to an Image Model which makes the relevant images, then back to the Canva editor.

Some important characteristics of this set up are that:
The user is still in the driving seat. They are in control of the tool, AI models just make the tool more powerful.
The deterministic software is still core. The overall output is predictable, even if elements are now probabilistic. If you press “create new presentation” it will always do that. It won’t create a video 10% of the time.
Language models provide a new UI for the deterministic software - describing what you want to happen, rather than clicking.
Cursor is another great example here. It is a software IDE (like a word editor for code), with extensive integrations with language models. Unlike Canva, these language models don’t all belong to Cursor, instead the app uses the API of language models like OpenAI, Anthropic and Google, in addition to some Predictive AI models of its own.
The characteristics still hold. The user is still the driver, the IDE is still the source of truth in the app, and the language models provide a dramatically new UI.
In Mode 1, even if the models end up handling 99% of the workload, the deterministic software retains primacy as the orchestration layer, and the human user as the conductor.
I think of this as the Tony Stark approach to AI productivity, based on the way he uses his AI (Jarvis) in the Iron Man movies. In the clip below you can see how he talks to the AI about the elements he wants in a suit design, which converts those thoughts into renders in CAD software, which remains the source of truth for the design. The language model makes suggestions and asks clarifying questions, but you could swap it out for another language model without too much disruption, as both the suit design project would remain constant.
The Mode 1 use of AI is mostly a sustaining innovation, rather than a disruptive one. It will make existing products better and generally favour incumbents.
The winner of AI driven presentation software is most likely going to be Google Slides and Microsoft Powerpoint. The winner of AI driven design tools are most likely going to be Figma, Canva and Adobe.
I think this is true for jobs too, where this mode applies. Some generative tasks will get handed off to an AI Model, but you, as the employee, will remain in the driver seat. You are the one who starts the process, you are editor with taste and discernment, you are the final decision maker. In this dynamic, existing employees will get power ups - tools to make them more productive at their jobs.
In some cases, of course, this might result in fewer of them being needed to produce a fixed level of output, but this is just as likely to result in firms seizing the opportunity to use a similar or greater number of people employed to produce even greater output.
ChatGPT is Mode 2
Personally, I am very excited by that first mode. I think there’s huge opportunities for foundational models, and language models in particular, to dramatically enhance the productivity of many business models, to reshape or overhaul others and even to create some new ones.
But that’s not where all the buzz is today.
What gets people deliriously excited is Mode 2, where foundational models are developed further to become the core of a new job, product, company or even industry. The idea here is that we can take these broad language models, which have an embedded understanding of (almost) all human knowledge and concepts, and use the same machine learning process to evolve them further into problem solving savants in a particular domain.
The best example of this is ChatGPT.
If you’ll recall, the foundation model just took some words as an input and predicted a series of words that could follow, so if you ask it a question it’s as likely to elaborate on the question as it is to provide an answer. A foundational language model is a simulator of webpages, books and articles, not conversations.
So OpenAI took their foundational model (GPT-3) and began to refine it to create an “Assistant.” They wanted to teach it that one of these was a bad completion and one was good:
Context 1: [Where is the Eiffel Tower?] …
Output 1: … [asked Peter. “I think it’s in Paris”, replied Jane]
Context 2: [Where is the Eiffel Tower?] …
Output 2: … [The Eiffel Tower is in Paris, France]
The first is a book simulator, but the second is a conversation simulator.
To teach “conversations” to the model, they fed it hundreds of thousands of examples of questions and associated helpful answers. To accomplish this, they hired lots of people to manually write out good answers to these questions, which they could use as training data.
The humans were also given varying “contexts” like “Oh really, tell me more about that” or “I’m so bored today” and were asked to type what they believed would be the ideal next reply in the conversation.
With this new training set of conversational data, OpenAI could refine the language model to become a conversation model. This turned out to be not all that difficult. The language model already had the core concepts of questions and answers embedded within it, it already “understood” the content of the answers, it just needed to learn the pattern of a conversation.
The language model has now been evolved into a conversational model. In some ways, you can think of this as a narrowing. The post-training made it less good at being a broad book & webpage simulator, but very good at one specific domain - conversations.
OpenAI then wrapped this model with some standard software. They build a UI that looks like a messaging app. Every message gets encased with [user] or [assistant] to delineate two sides of a conversation. They also hardcode some hidden initialising text into ever conversation, like:
You are ChatGPT, a large language model trained by OpenAI.
You are a highly capable, thoughtful, and precise assistant. Your goal is to deeply understand the user's intent, ask clarifying questions when needed, think step-by-step through complex problems, provide clear and accurate answers, and proactively anticipate helpful follow-up information. Always prioritize being truthful, nuanced, insightful, and efficient, tailoring your responses specifically to the user's needs and preferences.ChatGPT is the first of what I’m calling Mode 2, which has the following characteristics:
The broad foundation model is refined, through training, to do one specific thing really well. (In this case, have assistant-like conversations).
The model is the core orchestrator, so traditional software is used as scaffolding around the new model, to add deterministic elements where they’re needed (In this case, the chat UI, safety features, billing etc.)
The model is core, so the user is no longer in a deterministic driver seat. They can’t predict the output based on their input. Instead they are creating the context for the system to perform.
OpenAI successfully trained a language model to be good at conversations and three years later it’s earning $10 billion dollars per year. Mode 2 is pretty successful!
The big question now becomes, what else can we train foundation models to be good at?
Mode 2 Will be Disruptive
Unlike Mode 1, where the change is likely to be sustaining, Mode 2 will be disruptive.
Systems that are mostly language based are first up to be disrupted. This includes jobs.
Look at customer care, for example. If you can feed a language model on historic customer care transcripts, you can very plausibly refine one to be great at customer care conversations. You can even make it specifically, narrowly great at customer care for your organisation.
There are upfront costs in preparing the data and running the refinement training, but the ROI seems obvious and inevitable.
Writing code falls into this category too. Huge amounts of the job involves generating language (code). And so, in a somewhat ironic twist, San Francisco’s greatest minds have been refining models to get better and better at automating their jobs.
I know their job also involves co-ordinating with colleagues, setting priorities and many other tasks, but “writing code” is a huge proportion of the value-add. I am confident that we will find new uses for brilliant software engineers, but the disruption will be abrupt and difficult.
Disruption is most likely coming if your job, product, company or industry can most be described “Unstructured or unpredictable inputs are used in a system whose core concepts can be described in language, and the solution doesn’t need to be a predictable, rigid outcome.”
Can Mode 2 Let Us Wish For Infinite Wishes?
In this post I have described two great leaps in Machine Learning which acted almost as cheat codes to work around a limitation in the technology.
The primary limitation is that the process of training will make a model that is incredibly good at just one single thing. The first leap was to make that one thing “language”, which contained descriptions of all the other things.
The second leap was to train the language model to be good at “helpful conversations”.
I find these leaps to be so impressive because they feel like the tech equivalent of telling the genie you wish for more wishes. Hearing “you can only train one thing” and making that thing be an incredibly flexible, horizontal concept.

Are there be more of these leaps we can take?
It seems so!
There are three domains in particular that hold the most promise, each of which is currently at a different level of maturity:
Using Tools
Reasoning
Completing Tasks
Reaching For An Other Tool To Use
Tool Use is the most mature of these three. When you ask an AI Assistant (like ChatGPT) a certain set of queries it will pass the request off to another tool, rather than trying to generate an answer itself.
This can sometimes be another foundational model - like when you ask it to generate an image - or it can also be some form of deterministic software. AI Assistants now commonly use search functions to find and pull in new data to their context windows, they can write and execute python code for doing deterministic calculations and they can save certain data into databases, creating documents, memories and preferences for longer term retrieval.
If this tool use continues to grow, it might shift more domains from Mode 1 into Mode 2, where the “Assistant” or “Conversation” Model is the core orchestrator of the software, but it delegates individual tasks to other models or coded software in certain circumstances.
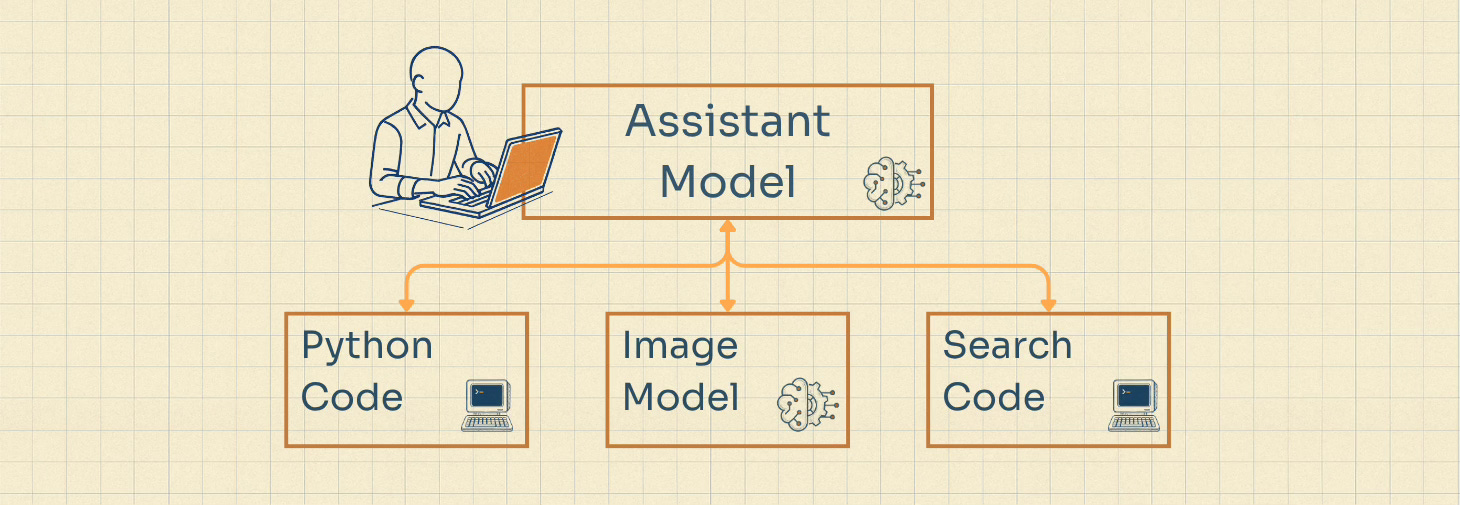
I think the limiting factors to exponential growth for Tool Use are:
It’s great if you want an ad-hoc solution, for a novel query or a once off process, but I still think task-specific software for repeated, with persistent artefacts and predictable outcomes, will benefit from Mode 1.
New Tool Use is currently being programmed by humans, and expanding at the pace of standard software development.
Learning The Shape of Reasoning
Reasoning is a recent, but profoundly powerful development. Much like “Conversations”, this step change has been achieved by training and evolving the language models further. We didn’t know how to code the models to Reason better, they figured it out themselves.
One significant limitation that language models face stems from the fact that they output tokens sequentially. One word, then the next, then the next. This means that they often get rabbit-holed. Once they go down a path, they can’t back-track.
For the first year or two, assistants like ChatGPT were quite bad at reasoning problems like this:
Context: “A train travels 60 miles per hour for 2.5 hours, then 40 miles per hour for 1.5 hours. What is the total distance traveled?”
Output: “60 miles. This is because it travels 30 miles for 2.5 hours, then 30 miles for 1.5 hours”
A Conversation Model fails at challenges like this because:
It starts by generating two tokens: “60 miles”. Generating these initial tokens is a very computationally light process. It’s just generating a pattern, not doing actual calculations. “60 miles” fits the kind of shape of an answer to this kind of problem.
Once it has issued the first two tokens, they then become a fist part of the context for the remainder of the sentence - so it just has to hallucinate some reasoning for the first answer it gave. It has backed itself into a corner. Once it has started down the path, and it has to follow through.
In late 2024 researchers discovered the hack to get around this. What if we could refine a language model by training it on the domain of “reasoning out problems”.
This was achieved by collating a data set of problems which have known answers, like the train question above. You run these through your foosball machines and you start to get reasoning patterns that might look like:
Output A: “60 miles. This is because it travels 30 miles for 2.5 hours, then 30 miles for 1.5 hours”
Output B: “This looks like there are three calculations to be made, one for each segment of the journey, then adding the two segments together. First I have to multiply 2.5 by 60. Then I should multiply …. [and so on]”
Things that look like Output B tended to find the right answer more often. They generated tokens in such a way that allowed for a more methodical chain of reasoning.
The step change here is that we trained language models to be better at a new singular thing - reasoning. We trained them (and are still training them) to get better at producing patterns of strings of language tokens that solve problems.
So now, instead of starting with the answer, reasoning models start with words like “I think the way to approach this is..” and follow a meta-pattern of regularly interrupting themselves to say “let me double check that” or “let me verify that with a different approach”.
This has been a profoundly successful approach, especially because it could benefit from being developed through training, rather than being coded. This has only been possible for reasoning on problems with defined solutions, where we can tell which versions of the foosball table “succeed” or “fail”.
It works well for a math problem, but it doesn’t work as well for problems with more subjective outcomes. Language Models are still quite bad at writing jokes, for example, because we can’t automatically grade the quality of a million versions of the same joke to train a “humor model.”
To do this with current processes, we would need to do something like hiring a thousand great comedians and get them to write a thousand jokes a day for a few years straight.
This is cumbersome, but it is being tried! It is how OpenAI first created their ChatGPT models after all. That’s why jobs boards are now full of listings like this:

Is Agentic “Task Completion” Also a Cheat?
Another exciting possibility is that you could tokenise all of the steps involved in a task - like visiting a website and booking a flight - and refine a model to learn their patterns.
People working on this call these kinds of models “Agentic”. They believe that we can further refine and evolve Language Models to describe the underlying “patterns” in task completion, so that they can generate a “sequence of actions” to help with any task.
We haven’t got much working very well quite yet. So far, the limits here seem more imposing, for a couple of reasons.
It’s unclear whether “task completion” is too broad of a category to learn and then probabilistically apply to tasks which, for the most part, require predictable and structured inputs. We might end up needing to train for subsets of tasks separately - like an Email Manager Model, a Calendar Manager Model, a Travel Agent Model etc.
Reasoning Models were mostly able to overcome the chain-of-tokens limitation that brought models down dead-end paths, but this will be a lot more difficult for longer tasks that involve many more steps over a much longer period of time.
The training data is harder to find for this AND the training time is very long, if you’re getting a model to perform an hour long task over and over again.
How To Predict The Economic Impact of AI (The Summary)
Let’s put a bow on this post and summarise what we’ve learned and how we can apply it.
Machine Learning is a profound new technology. If we have large amounts of data and expect a good ROI on the time and energy, we can train Models which detect patterns in that data and can make predictions (Predictive AI). These predictions have domain-specific applications like fraud detection, customer segmentation, clustering, recommender systems, language translation, image analysis and much more.
When we use Machine Learning to predict the next token in a sequence, we get Generative AI. Tokens can represent words in a sentence, pixels in an image or video, wavelengths in a sound file. This gives us Foundation Models. It is unclear when the ceiling on this will approach will be reached, but when it is reached it seems likely that it will become cheaper and easier for many companies to produce these foundation models.
Mode 1: In some cases, Language, Image and Audio Foundation Models will be used as component parts in a system, but won’t take over the orchestration layer. They will make existing orchestrators (software, employees, companies) more powerful. It will favour incumbents (bigger companies, older employees) over disrupters (new companies, junior employees).
Foundation models can be refined to do a specific thing really well. Rapid early progress in Conversation and Reasoning models might suggest that these wins will continue at pace, or even accelerate when we discover how to make a model that is specifically good at making other models (we can wish for infinite wishes). Conversely, we might just be discovering the “low handing fruit” quickly, but after that all additional gains will have to come from employing tens of thousands of people to type out training data, or to code specific tool use (we can only wish for 3-5 extra wishes).
Mode 2: Foundation models, or their refined versions, become the core orchestration layer. In particular, Conversation or Assistant models. This is disruptive. New products and companies will emerge. Completely new job types will emerge and old ones will vanish. The extent to which you think this will happen should depend on your optimism around the number of step-changing wishes we have left, or the number of years we will have to wait between them. If some of these step-changes deliver aggregator effects (e.g. continuous usage helps the model learn and get better), then expect a small number of big winners to emerge, like what happened in search.
Personally, I think Mode 1 will be a juggernaut. It will provide a new capability to a very wide array of business models in all sectors of the economy. Some will be transformed, but most will just be given a substantial productivity boost.
I think Mode 2, as the technology currently stands, will be rapidly disruptive in a much smaller (but still substantial) number of industries. Customer care. Advertising. Agencies & Consulting. Probably Legal and medical too, but slower because they’re heavily regulated.
I am a little bit more sceptical about how many wishes we have left to juice out of predict-the-next token based systems, such that I don’t think we’re on a clear path to AGI. I do think there will be lots of creative ways to combine them with deterministic systems and each other and that the next 5 years will produce 1-3 more “Reasoning” level jumps. So I expect Mode 2 to be substantially disruptive, probably at the level of something like the App Store model, or digital advertising.
I intend to cover this all here on this substack, to analyse and explain all the technical developments, the business model impacts and the economic reactions. I hope you’ll join me for the journey, and share some of your predictions too!
Really the engineers would have been at Tegic Communications, the company who made the original T9 predictive text
Most notably, Google’s 2017 paper on the Transformer - https://en.wikipedia.org/wiki/Attention_Is_All_You_Need
Excellent post! I run the YouTube channel Unlearning Economics and I really enjoyed your explanation, so much so that I may use some of the arguments and images for a video I'm making about AI. Would you be alright with this?