

What Happens If AI Is A Bubble?
How Would We Know? What Would The Fallout Look Like?
The level of capital investment that is happening in AI right now is staggering.
Early last year I raised an eyebrow at Sam Altman’s call for ‘trillions’ of dollars of investment, noting that it implied we would “need to reallocate about 6% of all the world’s industrial productive capacity to the development of AI models”. Today that figure doesn’t seem quite as unimaginable.
The investments this year have been so large that they are significantly reshaping the US GDP figures. Paul Kedrosky estimates that:
AI capex contributed perhaps 1.3% of the 3% GDP growth in the quarter, around 40%
This (combined with the effects of tariffs) leads to headlines like “The Weirdest GDP Report Ever” from the WSJ. To get a sense of the scale of this impact, have a look at this comparison (also from Paul Kedrosky):
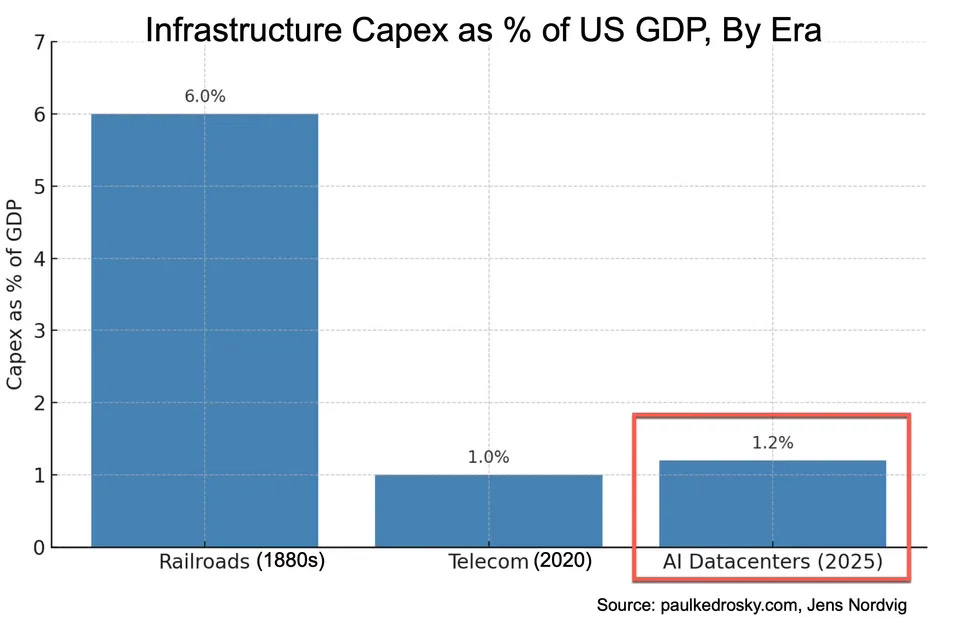
The level of investment is roughly equivalent to where telecoms were during the rollouts of both fibre in the Dotcom years and, more recently, 5G.
So what happens if this follows the path of previous CAPEX frenzies and ends in a bubble?
The Economics of The AI Labs
Most of this investment is driven by the “AI Labs” - companies who are training the next generation of Generative AI models, so I think a good place to start is by understanding their economics.
In an interview last week (from 33:00), Anthropic CEO Dario Amodei explained that it’s best to think about the economics and profitability in terms of the models, rather than the companies.
Here are some economic characteristics of the AI models:
Each model has a cost to train
Each model has a cost to run, and earns revenues from running
Over time each model gets more efficient to run, and margins get competed down
Over time each model gets surpassed by newer generations, and revenues get substituted away
And here are some good quotes from the Amodei, (he says the numbers are purely illustrative):
For every dollar the model makes, it costs a certain amount [to run]. That is actually already fairly profitable.
The big cost is the cost of training the next model.
Let’s imagine that in 2023 you trained a model that costs $100m. Then in 2024 you deploy the 2023 model and it makes $200m in revenue… but you spend $1bn to train a new model in 2024.
Then in 2025 the $1bn model makes $2bn in revenue and you spend $10bn to train the next model.
Think of each model as a venture and ask if each model is profitable. I invested $100m in a model in 1 year and got $200m back the next year, so that model had 50% margins.
In some ways this is similar to the Telecoms story. Everyone spent tens of billions to build out incredible 2G networks, which earned lots of revenue from usage (calls and text messages), which in turn funded the rollout of 3G networks, which all of the operators had to do in order to stay competitive.
The notable difference here is that for 2G, 3G, 4G and 5G, the level of CAPEX investment was roughly equivalent for each successive generation. In AI, this seems to be escalating rapidly between generations.
The path of progress isn’t just “let’s work hard to find new techniques and efficiencies, getting costs low enough to build the next generation”, it’s more like “last time we used the annual energy equivalent of a small town, next time let’s do a city.”
Each new generation takes about 10x the number of GPU hours to train than the last one, which is the first sign of a “runaway train” effect that might lead to a bubble.

The precarity of this growth is only heightened by the fact that the value of each new model depreciates so rapidly.
Every few months one of the AI Labs finds a new way to cut inference costs and therefore drop the prices. As Benedict Evans says:
An LLM is the most expensive and fastest-depreciating asset in tech history
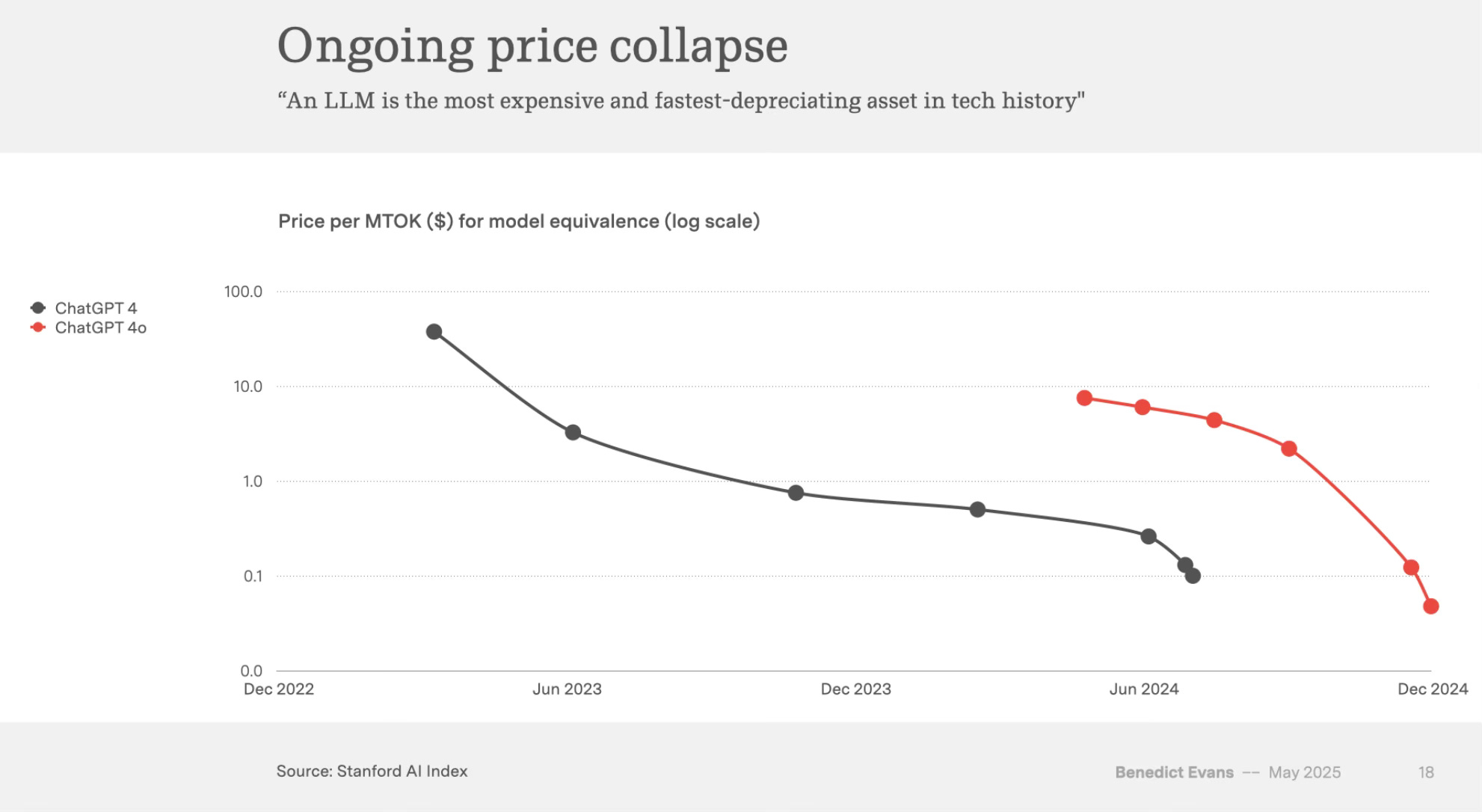
This is happening because we keep finding new ways to make them run more efficiently, but it’s also happening because each generation of model seems to be both incredibly expensive to make and not very expensive to copy.
Training an AI model means running millions of experiments until it discovers some underlying pattern that exists in the world - like language, or code writing or reasoning. This is valuable because those patterns are almost impossible for humans to describe to a machine, and therefore automate.
It seems, however, that it’s relatively trivial for a frontier model to “teach” that pattern to other models. And so every AI Lab that invests hundreds of millions (and soon billions) into a new generation of models seems to have about a 6-12 month window before it becomes commoditised.
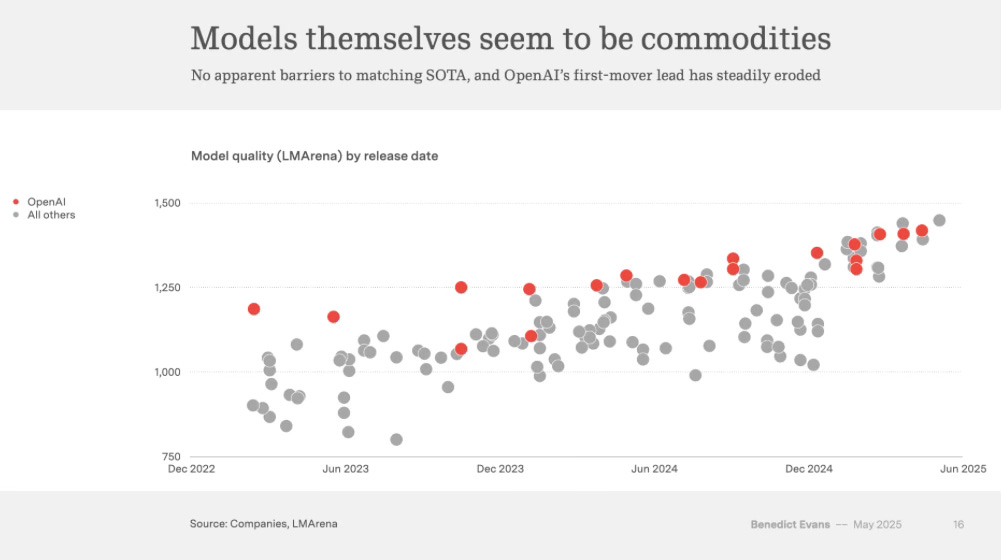
None of these companies have figured out how to develop large defensive moats (beyond brand). No lab has figured out recursive self-improvement. There appear to be very few “network effects” at the model layer, whereby ongoing usage helps you gain improvements such that a few of the most popular leaders start breaking away from the pack.
But the revenue is real
To recap what we’ve covered so far - if you’re an AI Lab in 2025 you are facing the following facts:
This year you’re going to have to spend 10x more than you did last year to build the next generation of models
They will massively cannibalise the revenue of the incredibly expensive models you just built last year
You have less than 12 months before everyone else has the same capability
You need to earn enough in that window to make the investment worthwhile
Luckily for you, number 4 seems to be working! (So far, and for some).
Since 2022 Anthropic, for example, have had annual recurring revenues of $10m, then $100m, then $1bn, and now $8bn(est). That’s pretty much a 10x in revenue every year, which is… insane!
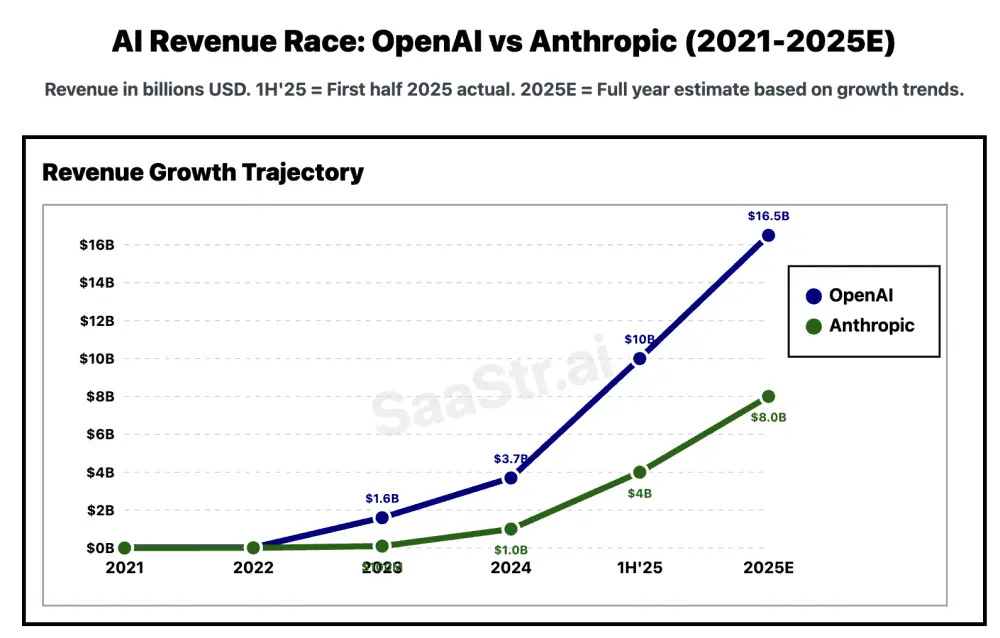
Each generation of new models represents such a leap in capabilities that it is generating massively more economic value, and the AI Labs seem to be capturing a healthy portion of that as revenue.
Right now it makes economic sense to keep 10x-ing your Capex expenditure for each new generation, as long as the capabilities keep 10x-ing too….
What Happens Next?
There are two bull case scenarios which would significantly reduce the chance that this is a bubble.
The first is that the AI labs discover some network effects. If two or three of them find ways to translate high usage volumes into ongoing model improvement. This would mean that investing to be on the frontier would continue to be worth it.
The second is that we get a big technical discontinuity by developing models that can improve themselves. This is recursive self-improvement - the AGI take-off scenario.
There is a lot of FOMO driving investment right now, in the fear that either of these two might be imminent. But… and I can’t stress this enough… we don’t have much of either right now.
It’s possible that there is some small amount of usage-network effects happening, but that they’re just being obliterated by the 10x capability improvement with each new generation of models. So they could emerge over time.
The Merry-go-round Will Stop
These two bull cases had better start to materialise soon, because we only have a few more rounds of 10x-ing left to go before we have to stop. Eventually we will run out of both GPUs and electricity, or at the very least they will become bottle-necking supply constraints.
Even without these natural constraints we might hit economic constraints. The marginal benefits from each new generation might diminish. As Aaron Levie says:
In 5 years we won’t need “infinite” intelligence applied to handling customer support tickets
I worry, however, that we won’t know that we have surpassed the economic constraints until it is already too late to pump the brakes.
In this sense, hitting energy and GPU bottlenecks might actually be a positive for avoiding a bubble.
In this scenario, all of the players in the market face the same constraint, so they can’t take that last leap to 10x their CAPEX, only to discover that the new models aren’t an order of magnitude more capable (or even if they are, they might still not be an order of magnitude more economically valuable).
And If The Bubble Does Pop?
It will be bad for many of these companies, but it might not be too terrible for the rest of us.
One upside is that there will be hundreds of thousands of GPUs sitting in data centres, not being used up in massive training runs and available to run inference - an activity which we already know is hugely economically valuable.
We will hopefully also have invested a lot of additional CAPEX into sustainable energy solutions, which will now have some extra capacity to help with CO2 reduction.
If models continue to be commodities, we will also live in a world where all of the most advanced capabilities are widely available, mostly open sourced or relatively cheap. Even if we’re just in a “training bubble” right now, we will have discovered the weights that unlock incredibly powerful capabilities. That won’t be “unlearned”.
In this sense, the current boom is even better than the equivalent in railroads and telecoms as it will leave us with built infrastructure AND unlocked knowledge.
Standard Recession or Credit Crunch?
The current financing models for AI training will also likely limit the fallout of a pop for the rest of the economy. Let me explain briefly the two broad types of recession that could result:
The first scenario is that all of this inflated CAPEX has mistakenly reallocated large portions of the productive capacity of economy towards AI model training, and some other businesses have also re-organised themselves around the expectation that this will continue. (Sometimes even unknowingly, like the shop selling uniforms for the workers building data centres).
If this unwinds, it will drop GDP growth substantially. This is because it will take time to re-allocate those resources (people’s jobs, electricity, land use, supply chain) away from AI model training and towards something else. If this time is long, that could be a recession. This is what the Dotcom bust looked like.
A second scenario could arise if the AI CAPEX is financed by credit. Financial credit is a form of time travel - Instead of spending a portion the revenue that we earned in the past, credit lets us pre-spend a portion of the revenue that we will earn in the future. When we use credit to invest in productivity growth, but that growth doesn’t materialise, the results are nasty.
For the last few years we have been in scenario 1 here, because most of this growth is being funded by company revenues, not debt.
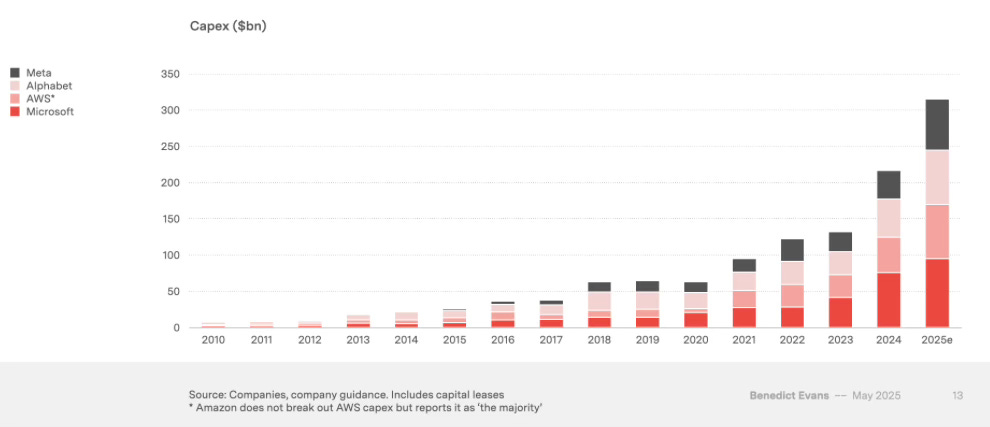
This can’t last forever. These companies may have revenue streams equivalent to the GPD of a small country, but they are not infinite. The Economist notes:
[C]apex is growing faster than [Big Tech’s] cashflows…The hot centre of the AI boom is moving from stockmarkets to debt markets…During the first half of the year investment-grade borrowing by tech firms was 70% higher than in the first six months of 2024. In April Alphabet issued bonds for the first time since 2020. Microsoft has reduced its cash pile but its finance leases—a type of debt mostly related to data centres—nearly tripled since 2023, to $46bn (a further $93bn of such liabilities are not yet on its balance-sheet). Meta is in talks to borrow around $30bn from private-credit lenders including Apollo, Brookfield and Carlyle. The market for debt securities backed by borrowing related to data centres, where liabilities are pooled and sliced up in a way similar to mortgage bonds, has grown from almost nothing in 2018 to around $50bn today…
CoreWeave, an ai cloud firm, has borrowed liberally from private-credit funds and bond investors to buy chips from Nvidia. Fluidstack, another cloud-computing startup, is also borrowing heavily, using its chips as collateral. SoftBank, a Japanese firm, is financing its share of a giant partnership with Openai, the maker of ChatGPT, with debt. “They don’t actually have the money,” wrote Elon Musk when the partnership was announced in January. After raising $5bn of debt earlier this year xAI, Mr Musk’s own startup, is reportedly borrowing $12bn to buy chips.
For now the big companies still have the cashflow from existing revenue lines to pay back these debts, even if the investments don’t pay off. The private debt to new entrants, however, is much more risky.
The Economist was already worried about the boom in private credit outside of AI, writing about them May in an article titled “How the next financial crisis might happen.” This is a trend worth keeping our eyes on.
Conclusion
I don’t believe we are in a bubble right now, because the productivity gains (as measured by revenues) from each generation of new models is very real.
We are, however, moving so fast that we might end up like Wile E Coyote, unable to slam the brakes once the cliff-edge materialised into view. Intra-company and intra-national competition is fierce. No moats have been discovered. Massive leaps in CAPEX remain the only way to stay ahead.
Resource constraints (GPUs, Electricity, Land) might actually hold some hope for a forced, collective deceleration, allowing us to approach the cliff edge in steps rather than leaps.
The longer the leaps continue, the more we will need to finance the CAPEX from the promise of future revenues, rather than savings from the past, and the riskier a bubble becomes to the wider economy.
AI is the biggest bubble in the history of tech. I think the peak will be in mid to late 2027 with a 90% collapse in valuation in the next 12 months after that.